
Biblioteques
He escollit una sèrie de recursos concrets per agilitzar l’obtenció de dades de forma automàtica:
- Requests i BeautifulSoup: Aquestes eines s’ocupen d’entrar als llocs web i examinar-ne l’estructura. Requests s’encarrega de l’obtenció del lloc, mentre que BeautifulSoup filtra el llenguatge HTML per extreure exclusivament les dades rellevants.
- Flask: Es tracta del marc de treball que converteix el programa en un servei actiu, gestionant les consultes dels clients i retornant les solucions corresponents.
- Google GenAI: L’enllaç imprescindible per transmetre la creació de contingut a la tecnologia d’intel·ligència artificial de Gemini.
Extracció
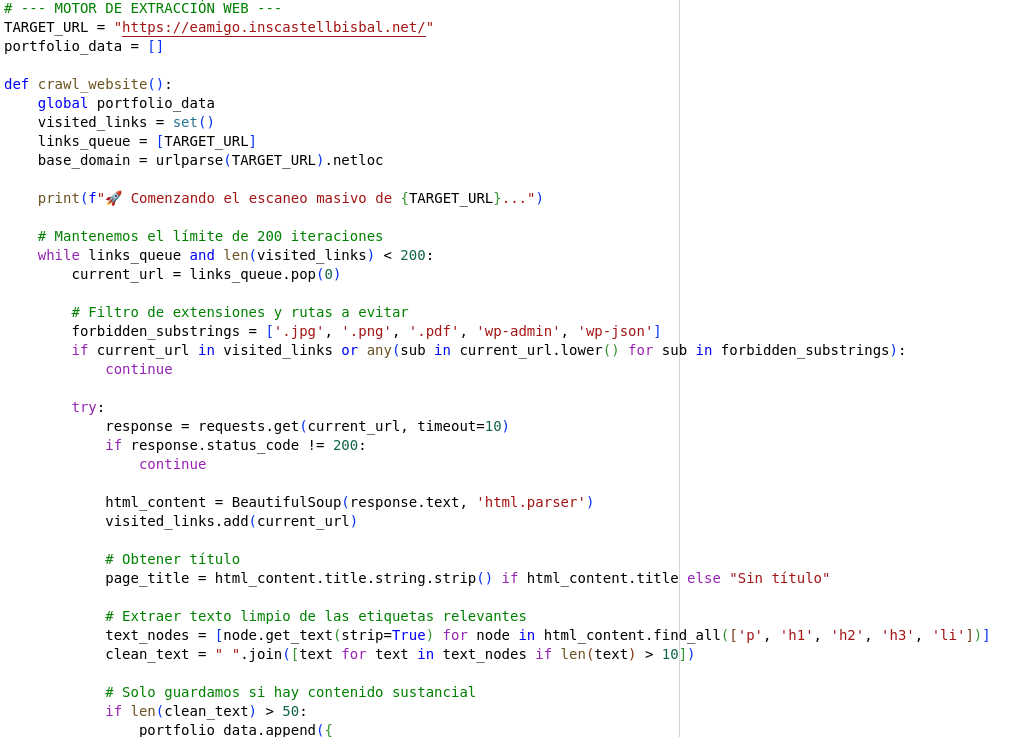
La funció de rastreig és l’encarregada de fer la feina de camp. Així és com funciona pas a pas:
- Punt d’accés: L’exploració comença a la meva pàgina principal i s’estén per tot el domini.
- Filtre de contingut: Salta entre enllaços interns amb un límit de 200 pàgines, descartant automàticament qualsevol fitxer multimèdia o PDF que pugui “mecanitzar” la lectura.
- Optimització de lectura: He configurat el script per suprimir el “soroll” visual (navegadors i footers). D’aquesta manera, la IA no analitza informació repetitiva i se centra exclusivament en el contingut real de cada secció.
I el Xatbot sap que respondre perquè li hem donat indicacions
Ngrok
Per connectar el xat del web amb el meu ordinador, utilitzo Ngrok. Com que no disposo d’un servidor fix, aquesta eina em facilita un enllaç extern que serveix de pont. Només cal enganxar aquesta URL a la configuració del WordPress perquè el xat sàpiga exactament on ha d’enviar les preguntes per ser processades.

